

Dans cette série d’article « Fondement de l’IA » de l’école d’intelligence Artificielle AI2, nous vous invitons à explorer en profondeur les concepts essentiels qui sous-tendent l’intelligence artificielle. Dans cette première partie, intitulée « Le Wording de l’IA », nous plongerons dans la distinction cruciale entre la data science, computer science et le machine learning. En démêlant ces termes souvent confondus, vous aurez une base solide pour comprendre les rouages de l’IA et ses applications dans le monde moderne.
Dans le monde de la technologie, il est facile de se perdre entre les termes techniques. Mais ne vous inquiétez pas, nous allons vous éclairer sur la différence entre la data science, le machine learning et la computer science, de manière simple et entraînante.
Fondamentaux de la Computer Science
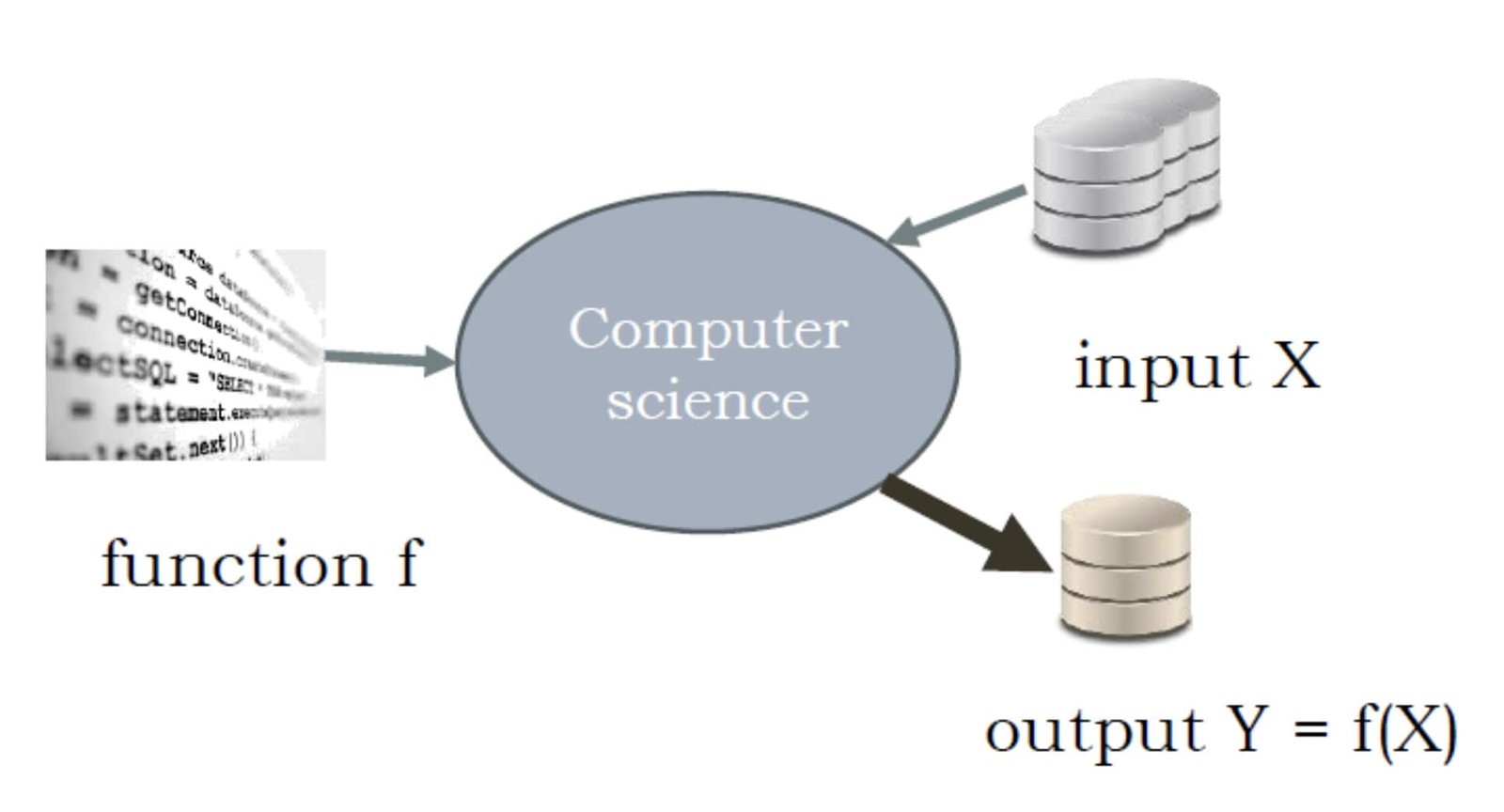
En informatique ou en programmation classique, nous saisissons des données en entrée (X) et attendons une sortie correspondante (Y).
Cette sortie est généralement une fonction de l’entrée, et notre objectif est de construire un programme ou une fonction qui génère cette sortie en fonction des entrées données.
Par exemple, dans le cas du théorème de Pythagore, où nous avons les longueurs des côtés a et b d’un triangle, nous voulons calculer la longueur du côté c, l’hypoténuse.
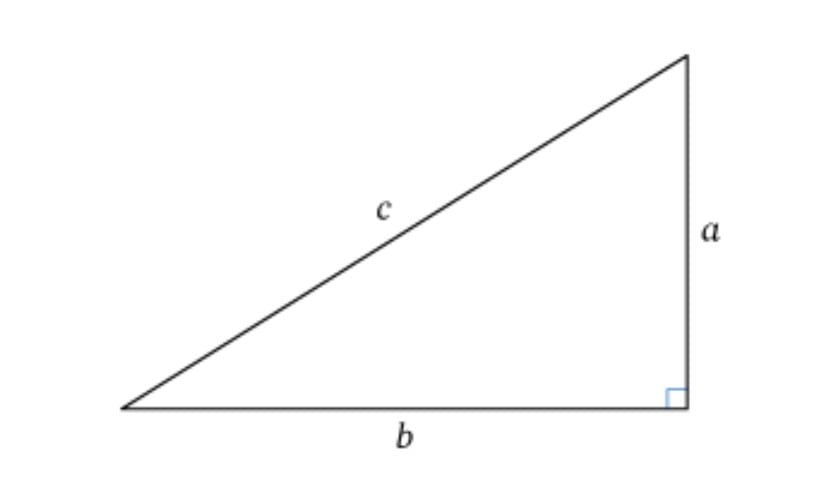
La fonction associée à ce problème est la racine carrée de la somme des carrés des longueurs des côtés a et b. ici
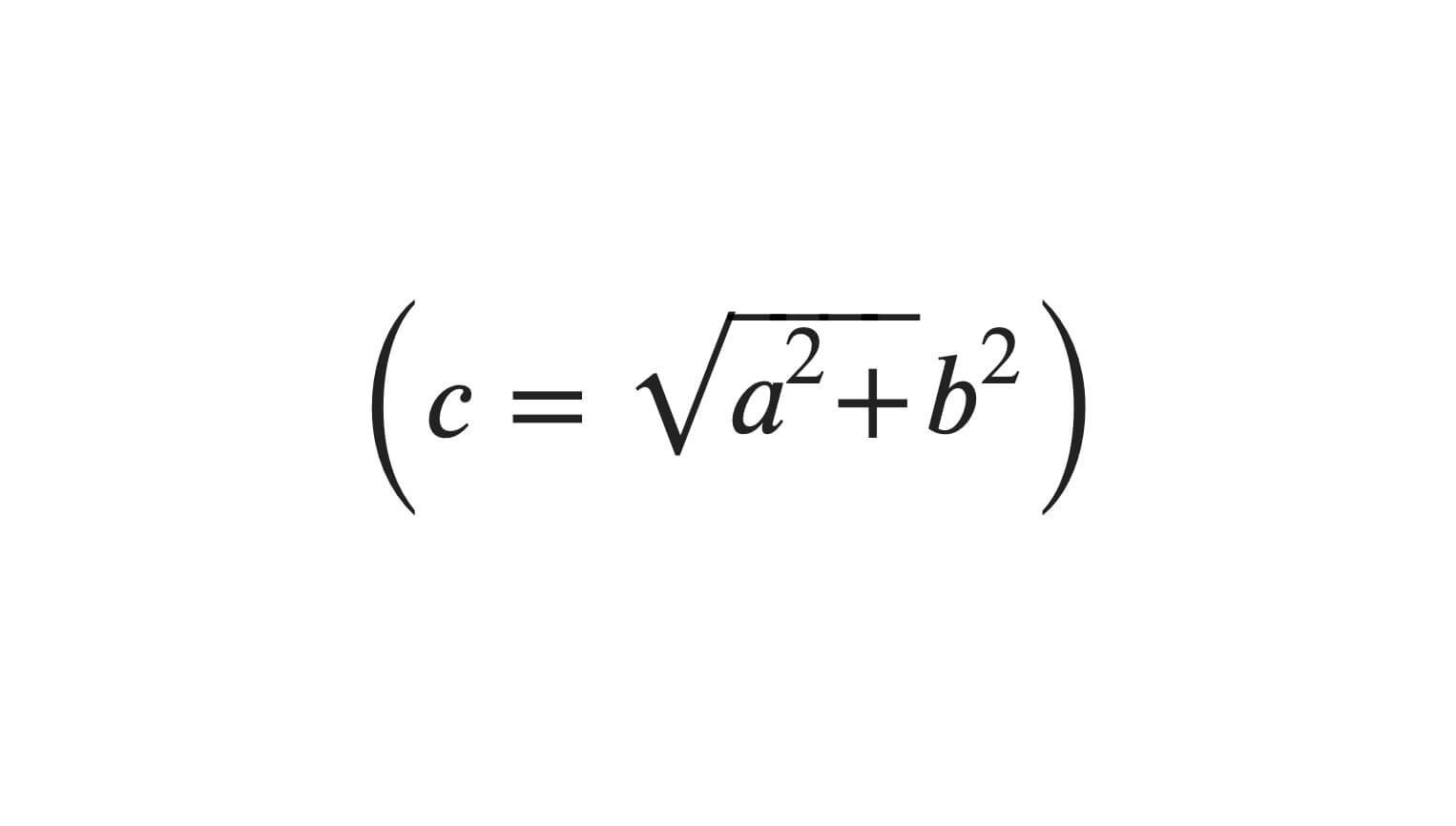
En résumé, en computer science, nous cherchons à déterminer la sortie Y pour une entrée donnée (dans cet exemple, les côtés a et b du triangle), puis nous développons un programme f ou une fonction pour calculer cette sortie (ici, la longueur du côté c, inconnue au départ) à partir d’une entrée X .
Data Science Expliquée : Modélisation des Données
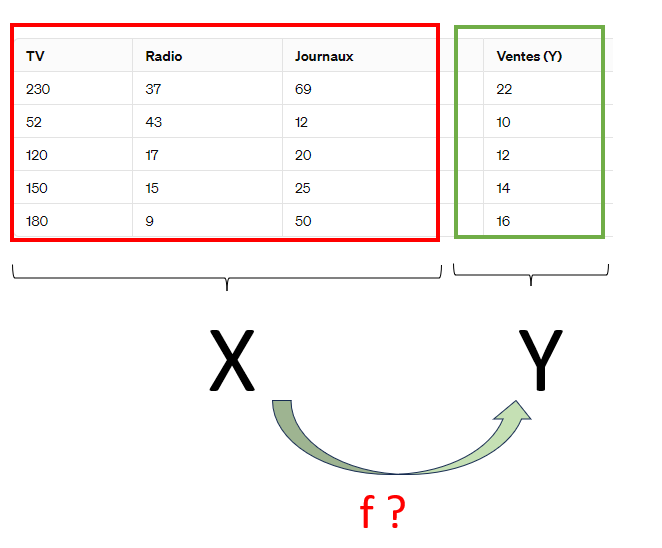
En data science, le paradigme diffère légèrement. Plutôt que de créer une fonction ou un programme pour générer une sortie Y à partir d’une entrée X, nous disposons généralement déjà d’un ensemble de données comprenant à la fois des entrées (X) et des sorties correspondantes (Y). Notre objectif est alors de trouver un modèle qui peut capturer la relation entre ces entrées et sorties ie trouver le modèle qui lie X et Y.
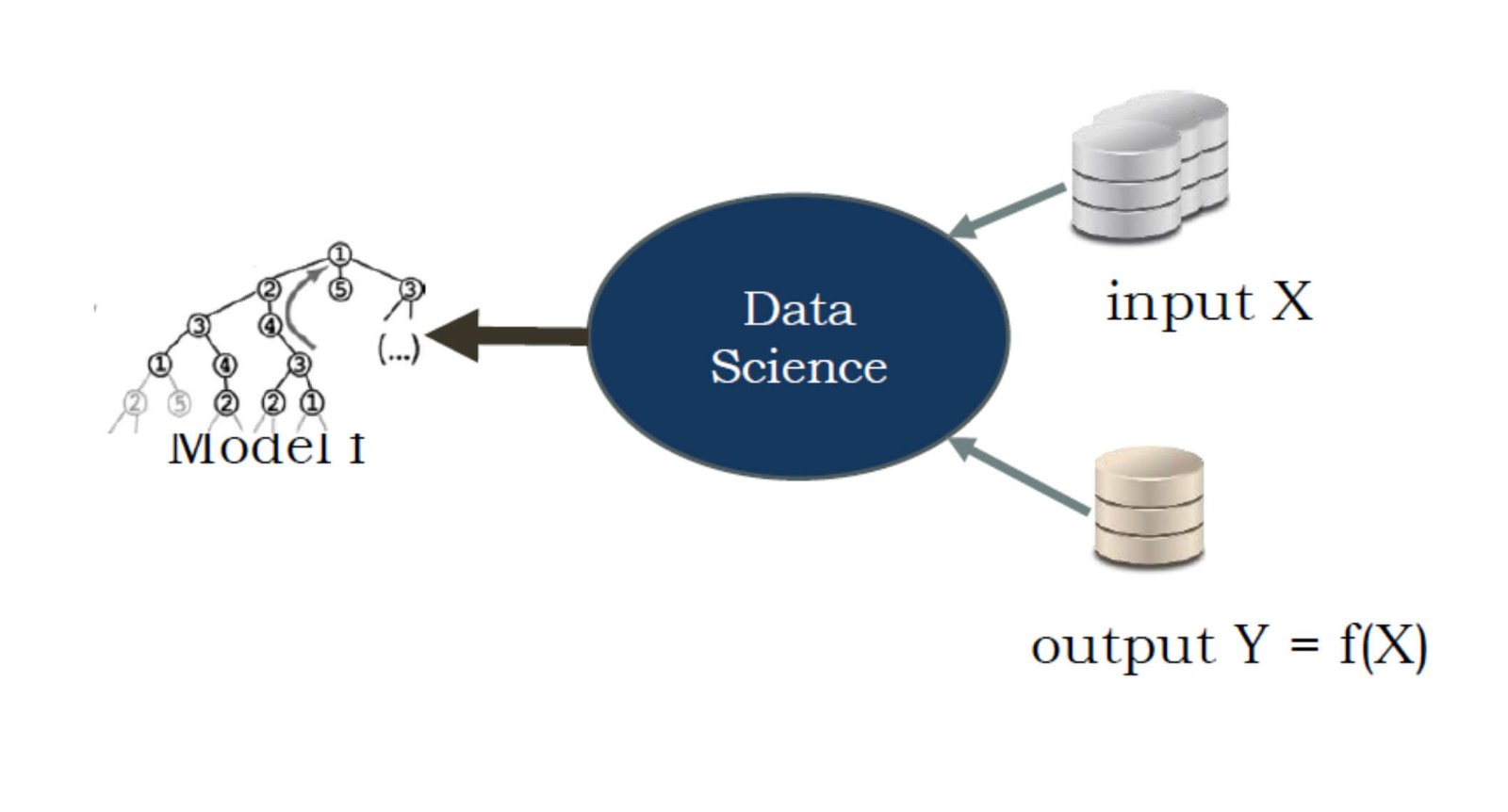
Prenons un exemple pour que ce soit plus concret, voici Microtech, une entreprise de vente de four micro-ondes :

En tant qu’entreprise vendant des micro-ondes, vous avez des données historiques sur les ventes passées par semaine et sur vos dépenses publicitaires dans trois canaux : la télévision, la radio et les journaux.
En utilisant ces données, vous souhaitez prédire vos ventes futures pour chaque semaine de l’année à venir.
Dans notre problème, nous avons:
Caractéristiques (X) :
- TV : Dépenses publicitaires à la télévision (en milliers de dollars)
- Radio : Dépenses publicitaires à la radio (en milliers de dollars)
- Journaux : Dépenses publicitaires dans les journaux (en milliers de dollars)
Réponse (Y) :
- Ventes de micro-ondes (en milliers d’unités)
Article connexe : Quel Bac pour IA ?
Ce que nous demandons au programme c’est de trouver le model qui lie le mieux X et Y. Pour un budget publicité TV, Radio, Journaux, je veux connaitre le volume des ventes y dans le futur. Pour cela je dois construire mon modèle sur le passé et l’appliqué mes prévisions de budget futur.
C’est un raisonnement qui est similaire au raisonnement inductif humain.
Imaginez une personne se réveillant amnésique au bord d’un lac. Elle remarque des cygnes, ces oiseaux, qui, habituellement, sont blancs. Pour elle cependant, ils apparaissent en noir.

Sans souvenir du contexte, elle associe instinctivement cette couleur à des caractéristiques animales telles que la longueur du bec ou la taille des ailes. Dans cet état de confusion, son interprétation des éléments environnants est altérée. L’esprit de la personne a ici crée un modèle à partir des Données X d’entrée (caractéristique du signe et la sortie Y (la couleur noire).
Cette personne va donc considérées que tous les cygnes sont de couleur noir en l’absence de nouvelles données pouvant modifier le modèle. C’est ce qu’on appelle l’induction.
Article Connexe : Le Salaire d’un Ingénieur en IA
De manière similaire, en data science, nous construisons des modèles pour comprendre les relations entre les entrées et les sorties d’un système. Cependant, comme tous les modèles dépendent des données d’entraînement, si les données ne représentent pas exhaustivement notre système, celui-ci peut générer des erreurs.
En effet, tous les modèles sont limités ; il n’y aura jamais de modèle parfait capable de prédire le cours d’une action à une heure donnée avec 100 % de certitude. Cela est impossible car nous ne pouvons pas capturer l’intégralité d’un système sous forme de données, et que le système évolue avec le temps. Le paradigme « le passé = le futur » n’est pas une vérité absolue mais relative.
Les systèmes changent, mais suffisamment lentement pour que nous puissions prédire les tendances d’un phénomène. C’est en cela qu’un grand statisticien, George Box, inventeur du box plot (méthode de visualisation graphique), nous dit que tous les modèles sont faux mais que certains sont très utiles.

Article connexe : Combien de Temps pour Apprendre l’IA ?
Considérons une entreprise de commerce électronique qui utilise la data science pour prédire les comportements d’achat de ses clients. Ils ont collecté des données sur les achats passés, les préférences des clients, les périodes de l’année, etc. En utilisant ces données, ils ont construit un modèle de prédiction des ventes pour différents produits.
Maintenant, supposons que cette entreprise décide de lancer une promotion spéciale pour un nouveau produit, un smartphone haut de gamme. Ils utilisent leur modèle pour prédire les ventes potentielles pendant la période de promotion, en se basant sur les comportements d’achat passés, les réactions à des promotions similaires, etc.
Cependant, même avec un modèle bien construit, il y a toujours une marge d’erreur. Peut-être que cette fois-ci, les clients réagissent différemment à la promotion en raison de facteurs externes imprévus, comme une nouvelle sortie concurrente ou un changement économique. Le modèle peut donc ne pas prédire avec exactitude les ventes réelles du smartphone.
Cependant, même si le modèle ne prédit pas avec précision, il fournit toujours des informations précieuses à l’entreprise. Par exemple, s’il y a une divergence entre les prévisions et les ventes réelles, l’entreprise peut utiliser ces informations pour ajuster sa stratégie marketing, revoir son produit ou affiner son modèle pour les futures promotions. En fin de compte, même si les modèles ne sont pas parfaits, ils sont extrêmement utiles pour guider les décisions commerciales et optimiser les performances.
Ainsi, en data science, nous cherchons à trouver le modèle qui peut le mieux représenter la relation entre nos données d’entrée (X) et nos données de sortie (Y), plutôt que de créer manuellement une fonction ou un programme pour effectuer cette tâche.
Machine learning vs Data Science
Le machine learning, ou apprentissage automatique, est une branche de l’intelligence artificielle (IA) qui dote les ordinateurs d’une capacité d’apprentissage autonome à partir de données. Contrairement aux programmes traditionnels qui suivent des instructions rigides, les systèmes de machine learning s’adaptent et s’améliorent continuellement en analysant les informations reçues.
Cette faculté d’apprentissage leur permet d’accomplir des tâches complexes avec une précision et une efficacité croissantes, sans nécessiter de reprogrammation constante.

Image grand public
Le grand public perçoit souvent le machine learning comme une sorte de chose magique. On imagine des machines surpuissantes qui apprennent par elles-mêmes à résoudre des problèmes complexes, un peu comme dans les films de science-fiction.
Article connexe : Formation IA sans BAC
Réalité pour les praticiens
En réalité, le machine learning est un domaine fascinant mais qui demande beaucoup de travail. Pour les praticiens qui utilisent Python et des bibliothèques comme Scikit-learn, le machine learning se résume à :
- Préparation des données: La majorité du temps est consacrée à la collecte, au nettoyage, et à la manipulation des données pour les rendre exploitables par les algorithmes.
- Choix et entraînement des modèles: Sélectionner l’algorithme adapté au problème, l’ajuster avec des paramètres pertinents (tuning), et l’entraîner sur les données préparées.
- Évaluation et amélioration: Analyser les performances du modèle, identifier ses points faibles et l’améliorer par itérations successives (pas toujours fructueuses!).


Scikit-learn est une bibliothèque Python populaire qui fournit des outils pour toutes ces étapes. Elle propose une large gamme d’algorithmes de machine learning déjà implémentés, évitant aux praticiens de partir de zéro. Cependant, il faut bien comprendre le fonctionnement de ces algorithmes pour les utiliser efficacement et en interpréter les résultats.
Conclusion
Dans ce premier volet de notre exploration des fondements de l’IA, nous avons clarifié les distinctions entre la data science, la computer science et le machine learning. Nous avons vu que la computer science se concentre sur la création de programmes pour générer des sorties à partir d’entrées données, tandis que la data science cherche à modéliser les relations entre des ensembles de données existants pour prédire des résultats futurs.
Enfin, le machine learning représente une branche de l’IA où les ordinateurs apprennent à partir de données pour effectuer des tâches complexes de manière autonome.
Dans notre prochain article, nous plongerons dans les différents types d’algorithmes de machine learning, en mettant l’accent sur la classification, la régression et l’apprentissage non supervisé, ainsi que sur les défis et les bonnes pratiques liés à leur entraînement et à leur déploiement.
Restez à l’écoute pour une exploration plus approfondie de ce fascinant domaine de l’intelligence artificielle !
Rejoignez AI2
Poursuivre une formation en intelligence artificielle est désormais possible à l’École d’Intelligence Artificielle AI2. Voici une liste de nos campus où vous pouvez accéder à des programmes de formation adaptés :
- Paris : Spécialisez-vous en intelligence artificielle au cœur de la capitale française.
- Bordeaux : Rejoignez notre campus dynamique pour une formation pointue en IA.
- Toulouse : Profitez d’un environnement riche en innovations technologiques.
- Bruxelles : Étendez vos compétences en IA au centre de l’Europe.
- Lyon : Intégrez notre programme dans une ville connue pour son dynamisme économique et technologique.
- Brest : Découvrez notre formation spécialisée dans un cadre unique et stimulant.
- Orléans : Bénéficiez d’une approche personnalisée et pratique de l’IA.
- Poitiers : Engagez-vous dans des études d’IA dans une ville jeune et dynamique.
Pour toute question ou pour obtenir plus d’informations sur les admissions et les programmes, n’hésitez pas à nous contacter. Notre équipe est là pour vous aider à naviguer dans votre parcours éducatif et professionnel en intelligence artificielle.